關於評估任務 ( Evaluation ),我覺得作為 NLP 系列的最後一個篇章還蠻合適的,在這將近一個月的時間內,我們有聊過的主題包括資訊檢索、文本生成、文本分類、翻譯任務、問答任務等等,而且也把最終學習目標 LLM 介紹到了。
隨著這幾年 LLM 的熱潮,各行各業也開始將其嘗試應用在自己的領域上,然而與此同時,大家對於 LLM 亂回答誤導使用者的擔憂程度也越來越高,從我這幾天介紹 Prompting、RAG 等技術就可以看的出來,最近這幾年的研究都在努力的讓 LLM 的回答變的更準確,在這個過程中,評估任務就成為了很重要的一部分。
我這幾天其實在網路上查了蠻多關於如何評估 LLM 的做法,並且從這些論文和調查報告中整理出了一些自己對於評估方式的理解:
關於這些論文更深入的部分,希望未來有機會可以再跟大家分享。
不過由於 LLM 可以應用的範圍和領域實在太廣,很難用一個指標就對它做出一個量化的評估結果,因此,接下來我會依據不同的 NLP 任務,介紹一些常用的指標。
文本分類算是所有任務中比較好評估的,因為它擁有明確的答案可以算分數,我們比較常用的指標包括 Accuracy 和 F1,這些評估方式大家應該都比較熟悉了,我們可以根據模型將文本分類後的結果,計算錯誤的比例和正確的比例,並應用這些指標來評估這個結果究竟好不好。
在翻譯任務中,也有很多指標可以用來評估模型的表現,我們以最基本的 BLEU 為例,它可以通過計算模型翻譯和正確答案之間的 N-gram 匹配度來決定翻譯結果好不好。
N-gram 之前沒有機會講,這邊稍微提一下,它是將整個句子以 N 個單詞為單位分成一組序列,比方說:
“Tom tripped and hurt his foot”
以 2-gram / bigram 的做法就會變成:
[”Tom tripped”, “tripped and”, “and hurt”, “hurt his”, “his foot”]
那麼我們就可以對模型翻譯和正確答案都做這樣的處理,然後比對他們的匹配性有多高。
此外,BLEU 還引入了 Brevity Penalty (BP) 的機制來避免模型生成過短的翻譯結果,並且整理出了最終像這樣的公式: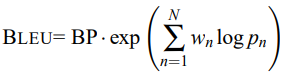
另一種指標是 METEOR,相較於 BLEU,它額外做了詞幹提取 ( Stemming ),讓相同的單詞更容易匹配到,此外,它還比較了單詞間的語意關係和語法結構,而不僅僅是匹配而已,因此也非常適合用來評估翻譯任務。
這裡要介紹的指標是 Rouge,它和 BLEU 的做法很像,也是從 N-gram 的匹配度來評估,然而和 BLEU 比較不同的地方是,它更偏重於 Recall,也就是希望參考文本中的內容越多出現在模型生成結果中越好,因此非常適合用來評估摘要任務。
我們先以比較簡單的任務來介紹評估方式,假設是以下這種形式的問答:
Query : Who won 2024 Taiwan presidential election?
Answer : Lai Ching-te
Model : Lai Ching Te
對於這樣只有單一答案的任務 ( Closed-QA ),我們可以使用 Exact Match (EM) 來評估,它會衡量模型的回答和正確答案是否完全一致,只有當回答和正確答案一模一樣的時候,才會得到分數。
所以像剛剛這樣的模型回應,儘管幾乎一樣了,還是會被判斷為 0 分。
不過在面對開放式問答 ( Open-QA ) 任務的時候:
Query : Who won 2024 Taiwan presidential election?
Answer : Lai Ching-te
Model : Lai Ching-te won 2024 Taiwan presidential election.
這種 QA 任務就不適合使用 EM,我們可以使用 F1-score 去判斷模型回應和正確答案之間的匹配程度,或是通過語意相似度判斷兩者之間是否一致。
除了這些之外,其實還有很多指標值得拿出來討論,比方說:
此外,我想要多介紹的是 Human Evaluation 和 LLM Evaluation,人類評估一直都是最標準的解答 ( Golden Standard ),然而也因為它太過耗時而且無法自動化,所以才有了像上面那一大串的評估方式。
而 LLM Evaluation 則是比較新的評估方式,我們可以通過 Prompting 的方式建立一套評估規則,然後讓 LLM 去完成評分,這樣做的好處是 LLM 可以根據自己的理解來評估模型生成的回應,甚至是做出為什麼要這樣評分的解釋,而且在各種任務上都適用。
然而這種作法也存在著一些缺點,因為 LLM 本身可能存在偏見以及其它複雜的因素,導致它容易做出不穩定、錯誤的評分,因此距離能夠實際應用在通用的評估方式還有一段路要走。
參考 & 推薦文章
PS : 以上就是我對 NLP 相關評估方式的整理,如果有敘述錯誤的地方請提出來哦 ~

